from torchvision.models import vgg16, VGG16_Weights
from torchvision import transforms
import torch.nn as nn
from torch import cuda
from torch.utils.data import Dataset, DataLoader
class AnimalDataset(Dataset):
def __init__(self, path):
self.classes = os.listdir(path)
self.images = []
for i, cl in enumerate(self.classes):
self.images.extend(list(map(lambda x: (path/cl/x, i), os.listdir(path/cl))))
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
path, label = self.images[idx]
X = self._read_image(path)
X = transforms.Resize((224, 224))(X)
return X, label
def _read_image(self, path):
img = Image.open(path).convert('RGB')
data = transforms.ToTensor()(img)
return dataThere is a big chace you have heard of CNNs before, not Cable News Network but Convolutional neural network and how they are used in computer vision. Traditional multilayer Perceptrons do not take advantage of the importance of locality of pixel dependencies, instead, it flattens the images and sort of treats them as tabular data. We have come a long way since then.
A brief recap of convolutions
in theory, a convolution at x tires to measure the overlap between two functions in a specified bound where one is flipped and shifted by x
\[(f*g)(x) = \int f(z)g(x-z) \; dz \]
However, when dealing with images, they are discrete objects (the pixels) hence the integral can be simplified into a sum and for a two-dimension tensor:
\[(f*g)(i,j) = \sum_a\sum_b f(a,b)g(i-a, j-b) \]
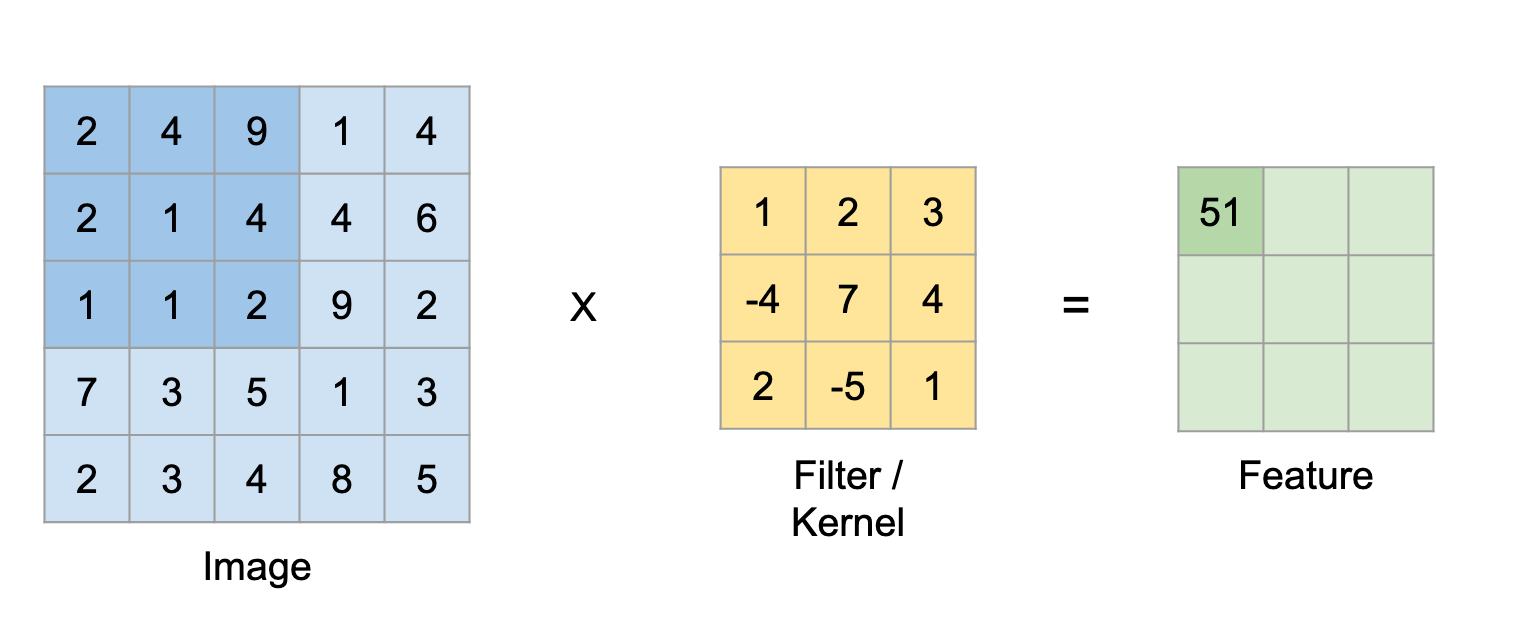
\(F_{(0,0)} = 2 \times 1 + 4 \times 2 + 3 \times 9 + 2 \times -4 + 1 \times 7 + 4 \times 4 + 1 \times 2 + 1 \times -5 + 2 \times 1 = 51\) …
a kernel, which also can be called a filter, tries to highlight or find a pattern in the image. In a complex deep learning model, the parameters of these filters cannot realistically be set manually or what filter is responsible for which pattern and what are even those patterns, instead, We just try to find a suitable architecture and hope that the kernels parameters are learnt properly.
Extracting Features
Lets attempt to extract features from known model, Vgg16 by (Visual Geometry Group) using consecutive blocks where each block is extracting a specific feature. First, we import the pre-trained module, by default Vgg16 output is designed for 1000, we can add a linear layer and try to train it only for our specific datasets, or we can use the model directly.
VGG model
The first step is setting up the Animal dataset using pytorch’s Dataset.
We notice 5 blocks ending in MaxPool2d, that will help us vizualize the different shape/feature obtained for each each block on different channels.
BLOCKS = {
1: (0, 5),
2: (5, 10),
3: (10, 17),
4: (17, 24),
5: (24, 31)
}
class Vgg16FeatureExtractor:
def __init__(self, model):
self.features = model.features
self.blocks = BLOCKS
def __call__(self, image, block=1, subplots=(2, 10)):
data, y = image
print(translate[dt.classes[y[0]]])
plt.imshow(transforms.ToPILImage()(data[0]))
print(f'extracting feature from block {block}')
channels = subplots[0] * subplots[1]
_, axes = plt.subplots(2, 10, figsize=(15, 5))
axes = axes.flatten()
for channel, ax in enumerate(axes):
im = self.features[:self.blocks[block][1]](data)[0][channel]
im = transforms.ToPILImage()(im).resize((200, 200))
ax.imshow(im)
ax.set_title(f'channel {channel+1}')
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
translate = {"cane": "dog", "cavallo": "horse", "elefante": "elephant", "farfalla": "butterfly", "gallina": "chicken", "gatto": "cat", "mucca": "cow", "pecora": "sheep", "ragno": "spider", "scoiattolo": "squirrel", "dog": "cane", "cavallo": "horse", "elephant" : "elefante", "butterfly": "farfalla", "chicken": "gallina", "cat": "gatto", "cow": "mucca", "spider": "ragno", "squirrel": "scoiattolo", "panda": "panda"}
dt = AnimalDataset(Path("animals"))
dataloader = iter(DataLoader(dt, batch_size=1, shuffle=True))
feature_extractor = Vgg16FeatureExtractor(model=vgg16(weights=VGG16_Weights.IMAGENET1K_V1))
example = next(dataloader)C:\Users\kaito_kid14\.conda\envs\deep\lib\site-packages\torchvision\transforms\functional.py:1603: UserWarning: The default value of the antialias parameter of all the resizing transforms (Resize(), RandomResizedCrop(), etc.) will change from None to True in v0.17, in order to be consistent across the PIL and Tensor backends. To suppress this warning, directly pass antialias=True (recommended, future default), antialias=None (current default, which means False for Tensors and True for PIL), or antialias=False (only works on Tensors - PIL will still use antialiasing). This also applies if you are using the inference transforms from the models weights: update the call to weights.transforms(antialias=True).
warnings.warn(First block
feature_extractor(example, subplots=(1, 10), block=1)dog
extracting feature from block 1

Second block
feature_extractor(example, subplots=(1, 10), block=2)dog
extracting feature from block 2

Last block
feature_extractor(example, subplots=(1, 10), block=5)dog
extracting feature from block 5

Conclusion
Hopefully this provides you an idea with how features that are being fed to a classifier look like. We have used VGG16 due to its simple architecture, also we are only showing the first channels given the subplot value. That being said, not every CNN model has a clear architecture that can be easily decomposed as as feature extractor and a classifier however it is achievable.
I hope this excites you about Computer vision as it did to me when I first came across this, in the next post, we will build on the idea of feature extracting to transfer the art and style to another picture